When accessing certain URLs from the Web Archive/Wayback Machine, you may encounter a ‘429 Too many requests’ error in your web browser. This error stems from the archival process of the URLs and is not a fault of the browser itself.
To address this issue, the first thing you can try is to enable Skip Proxy. You can access this by clicking the gear icon at the top right-hand corner of your screen and selecting “Browser Settings.” From there you can toggle the Skip Proxy setting off and on. This will prompt a browser to reload. After reloading, re-enter the URL to be captured.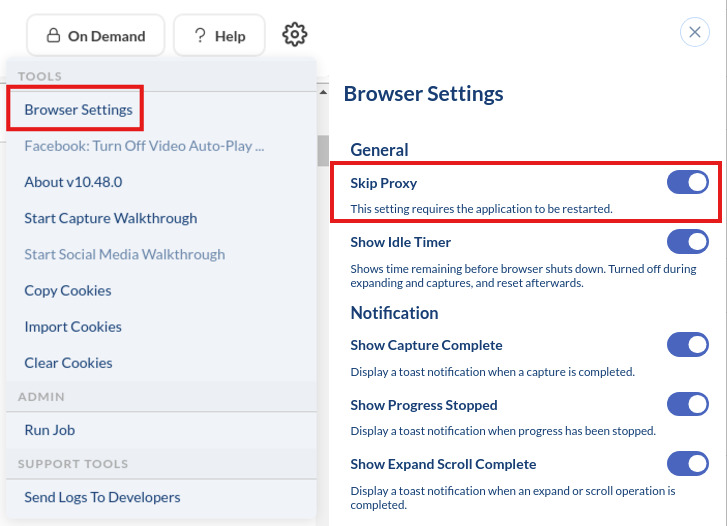
Skip Proxy allows specific websites or domains to be accessed directly without going through a proxy server.
An alternative method to capture such URLs is to make a Batch Web page capture.
How to Capture Wayback Machine With Site Crawler
The Web Archive site itself is too large for our Site Crawler to capture the entirety of, however, these methods below will help you get a crawl of the specific site on Wayback that you are wanting:
Using Keywords
The easiest way to ensure you are only getting the relevant content you need is to require a keyword/URL string. This can be set under our Advanced Crawl Options:
In this case, if you want to crawl https://web.archive.org/web/20210103052306/https://www.hubinternational.com, I would require the URL string “hubinternational.” This will prompt our tool to only generate and capture URLs that have that keyword, instead of crawling the entirety of the Wayback site. The site itself is fairly large and pulls a ton of URLs beyond the capabilities of our Site Crawler.
Crawling From The Date Page
Another crawl suggestion we have is to start your crawl from this calendar page if you want to get a history of the page itself (i.e https://web.archive.org/web/20240000000000*/https://www.hubinternational.com) You could then also use keywords to ensure you are only getting the content relevant to you!