Note that the Site Crawler is a paid feature. Please reach out to support@page-vault.com if you would like to inquire about adding Site Crawler to your plan.
What is the Site Crawler?
The Page Vault Site Crawler is a feature designed to automatically crawl websites and simultaneously make captures of those websites. It is ideal for users who need to capture multiple entire pages or sections of a small to medium-sized website.
The Site Crawler will collect URLs from the original domain. All external links will be excluded.
🕷️ What are common use cases for the Site Crawler?
- Quickly collect all URLs within a page, or up to 5 layers (subsequent pages) of a website. You can use this list to determine which pages or sections to capture using our Batch tool
- Save time and effort by automatically crawling and capturing an entire website or a website section, up to 5,000 URLs.
For an interactive demo, click here!
How do I Get Started with the Site Crawler?
There are two ways you can use the Site Crawler: through Capture Mode, or from the Page Vault Portal. We recommend starting crawls from Capture Mode for ease!
Crawling from Capture Mode:
- Click Capture to launch Capture Mode
- Navigate to the site you wish to crawl
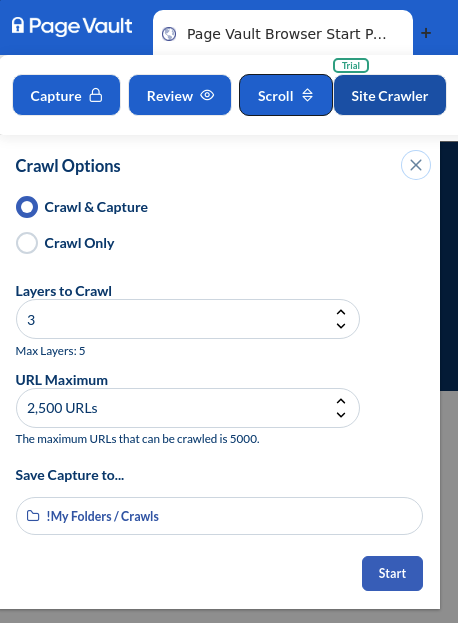
- Select “Site Crawler” and fill out the appropriate details for your crawl. Note that cookies are not required in this section, because the browser will store the cookies automatically. Before you start the crawl, be sure to click out of any marketing pop-ups.
- Select Start! You can close out of Capture Mode as your crawl will run in the background.
- Navigate back to the Site Crawler section in your portal to view the crawl progress.
Crawling from the Page Vault Portal:
- Log into your Page Vault account and select “Site Crawler” in the top navigation bar.
- Select New Crawl, and enter in the URL that you wish to crawl.
- If needed, enter in cookies. Learn how and when to manage cookies here.
- Choose which type of crawl you’d like to make:
- Crawl and Capture will crawl up to 5000 URLs and automatically capture each URL. The output will be a complete list of URLs and a PDF capture of each URL.
- Crawl Only will provide a list of up to 5000 URLs crawled from the website
- Select the number of layers you wish to crawl – if you are trying to capture an entire website, set this to “5.”
- Set the URL maximum. Please note that if you increase this to 5000, the capture process can take up to a couple hours.
- If you are capturing your crawled URLs, select a folder to which you will save your captures.
- Click Start Crawl!

Canceling, Deleting, Downloading Crawls
Once a crawl is started, you can cancel it at any time while it’s running. This is helpful if you started a crawl by mistake, or if you notice that the capture results have a pop-up obstructing the captured content. When you cancel a crawl, all the crawled and captured material will be saved to the crawl details page.
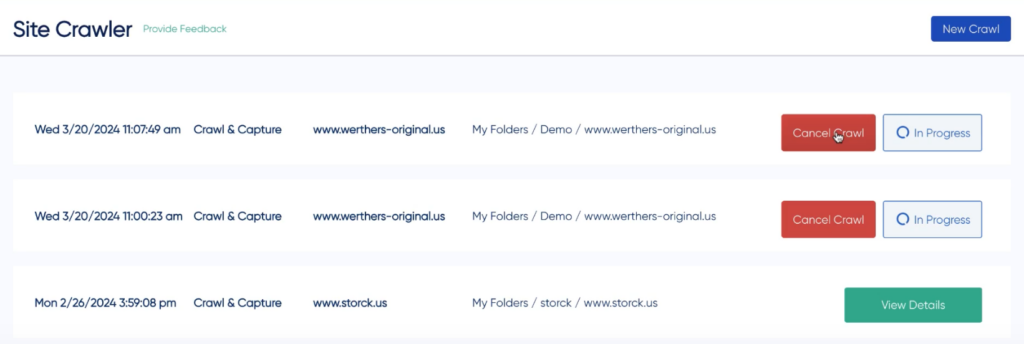
Once a crawl has completed, you are able to take a few actions on the crawl results.
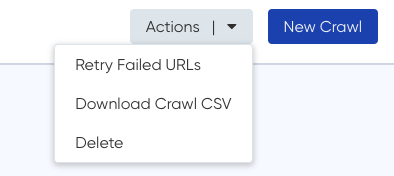
- Delete – this will delete the crawl record. Note that if you captured content during the crawl, the content will still be stored in your Page Vault Portal.
- Download Crawl CSV – this will download the URL crawl results in a CSV file. Captures will not be downloaded.
- Retry Failed URLs – occasionally, a URL’s capture will fail. This option allows you to retry any failed URLs to automatically attempt to capture them again.
Controlled Crawls: Refining Your Web Crawl Results
With our Controlled Crawls feature, you now have greater control over the URLs captured in your site crawls. This enhancement allows you to require or exclude specific keywords in the URLs, making it easier to filter out irrelevant content and target only the information you need.
How to Use Controlled Crawls
- Start a New Crawl
Begin by entering the URL you’d like to crawl as usual. Note that our crawler currently does not support social media sites. - Access Advanced Crawl Options
In the Advanced Crawl Options section, you’ll see two new fields:- Require (One Keyword or URL String): Use this field to specify a single keyword or URL pattern that must be present in every URL collected. For example, if you’re only interested in pages with the path
"/collections/womens-all", enter it here. Our crawler will ensure that only URLs containing this keyword are included. - Exclude (Multiple Keywords or URL Strings): Use this field to list any keywords or URL strings you want to exclude from your crawl results. Enter multiple keywords by separating them with line breaks. For instance, if you don’t need URLs with
"/news"or"/product/mens", add these terms here to filter them out.
- Require (One Keyword or URL String): Use this field to specify a single keyword or URL pattern that must be present in every URL collected. For example, if you’re only interested in pages with the path
- Optional: Add Site Cookies
If you need to include site-specific cookies to avoid capturing pop-ups or other marketing material, paste them into the Site Cookies field. - Run the Crawl
Once you’ve configured your crawl, start the process. Our system will gather only the URLs that match your specified criteria.

FAQs
Do I have to capture all the URLs that I crawl? No – our crawler lets you distinguish between whether you’d like to just crawl a website or crawl and capture a website simultaneously.
What are “layers”? Layers refer to the hierarchical structure of a website. The URL that you enter represents Layer 1. Any URL collected from that page will then become Layer 2, and all URLs on those pages will be crawled and will become layer 3. Site Crawler beta can capture up to 5 layers.
What types of URLs will be captured? The crawler will collect URLs include in a site’s page. External links, videos, and email domain links will not be included. Any duplicate links will automatically be removed.
What if I have two captures that are identical but the URLs are different? Occasionally, a website will have two URLs that point to the same page – resulting in two identical captures. In its current state, our crawler removes all duplicate URLs, but we cannot detect if two different URLs point to an identical page. If you are seeing the same URLs being captured multiple times, please reach out to support@page-vault.com